

技术速递:IPFS协议栈与场景模拟
技术速递:IPFS协议栈与场景模拟
发布日期:2019-07-09 浏览次数:1610
IPFS协议栈与场景模拟
IPFS至少有七层协议栈,从下至上分别为身份、网络、路由、交换、对象、文件、命名、应用(有些认为八层协议栈的存在应用层),每层协议栈各司其职,写成独立于上层,但上层依赖于下层。
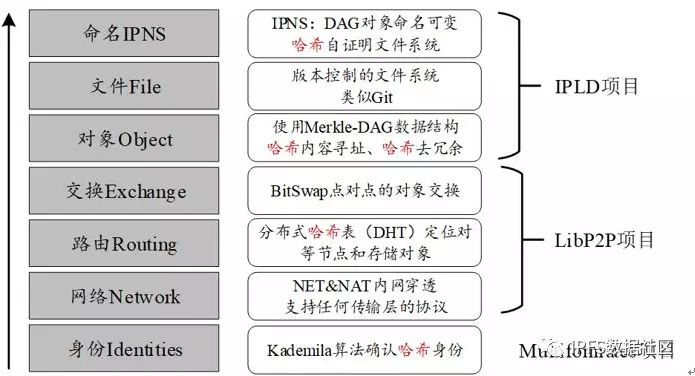
各层解释:
身份层和路由层可以一起解释。对等节点身份信息的生成以及路由规则是通过Kademlia协议生成制定,KAD协议实质是构建了一个分布式松散Hash表,简称DHT,每个加入这个DHT网络的人都要生成自己的身份信息(通过哈希生成的ID),然后才能通过这个身份信息去负责存储这个网络里的资源信息和其他成员的联系信息。
网络层比较核心,使用的LibP2P可以支持任意传输层协议。NAT技术能让内网中的设备共用同一个外网IP,我们都体验过的家庭路由器就是这个原理。
交换层,是类似迅雷这样的BT工具。
1.迅雷其实是模拟了P2P网络,并创建中心服务器,当服务器登记用户请求资源时,让请求同样资源的用户形成一个小集群swarm,在这里分享数据。这种方式有弊端,一位服务器是由迅雷统一维护,如果出现了故障、宕机时,下载操作无法进行。
2.中心化服务还可以限制一些下载请求,人们发明了一种更聪明的方式就是Bittorrent,让每一个种子节点所要存储的数据,通过哈希表存储在里面,BT工具相对不太受监管,服务更加稳定。
3.IPFS团队把BitTorrent进行了创新,叫作Bitswap,它增加了信用和帐单体系来激励节点去分享,我推断FileCoin有很大概率是基于Bitswap,用户在Bitswap里增加数据会增加信用分,分享得越多信用分越高。如果用户只去检索数据而不存数据,信用分会越来越低,其它节点会在嵌入连接时优先选择信用分高的。这一设计可以解决女巫攻击,信用分不可能靠机器刷去提高,一直刷检索请求,信用分越刷越低。请求次数和存储量的变量之间有一个比较精妙的算法,类似一个抛物线,前期可以容忍很多东西,达到一定次数后不再信任。
对象层和文件层适合结合来谈,它们管理的是IPFS上80%的数据结构,大部分数据对象都是以Merkle DAG的结构存在,这为内容寻址和去重提供了便利。文件层是一个新的数据结构,和DAG并列,采用Git一样的数据结构来支持版本快照。
命名层具有自我验证的特性(当其他用户获取该对象时,使用指纹公钥进行验签,即验证所用的公钥是否与NodeId匹配,这验证了用户发布对象的真实性,同时也获取到了可变状态),并且加入了IPNS这个巧妙的设计来使得加密后的DAG对象名可定义,增强可阅读性。
最后是应用层,IPFS核心价值就在于上面运行的应用程序,我们可以利用它类似CDN的功能,在成本很低的带宽下,去获得想要的数据,从而提升整个应用程序的效率。
新的技术取代老的技术,无非就两点:第一,能提高系统效率;第二,能够降低系统成本。IPFS把这两点都做到了。
RECOMMEND
场景模拟
1.加入IPFS网络,在网络中搜索叫ABC的文件(通过IPNS——去中心化的文件命名系统)
2.IPFS网络迅速索引区块链上的哈希值,反馈出搜索结果。
3.你支付一点FileCoin代币, 获取ABC文件缓存到本地,ABC文件不是从云或者服务器上下载下来的,而是由这个网络的参与者贡献的,它可能是离你最近的一个网络节点。这样的好处就是不仅不需要中间服务器,而且网络效率最快。
4.如果ABC文件恰好你周边好几个人都有,那IPFS网络会把这个文件拆成一小片一小片,节省了这些节点的储存成本,也让你用最具效率的方式下载到该视频。
5.这个视频文件缓存在自己电脑里,不仅自己观看,同时也为其他人提供资源。
6.另外也可以自己发布新内容到这个网络上,并且有机会获得FileCoin代币,因为你也为网络做了贡献。
---------------------
作者:Kevin_miu
来源:CSDN
原文:https://blog.csdn.net/a791693310/article/details/80612676
- 上一篇:IPFS的明星应用和应用意义
- 下一篇:[Filecoin]的项目评


